Python 으로 csv 파일 다루기
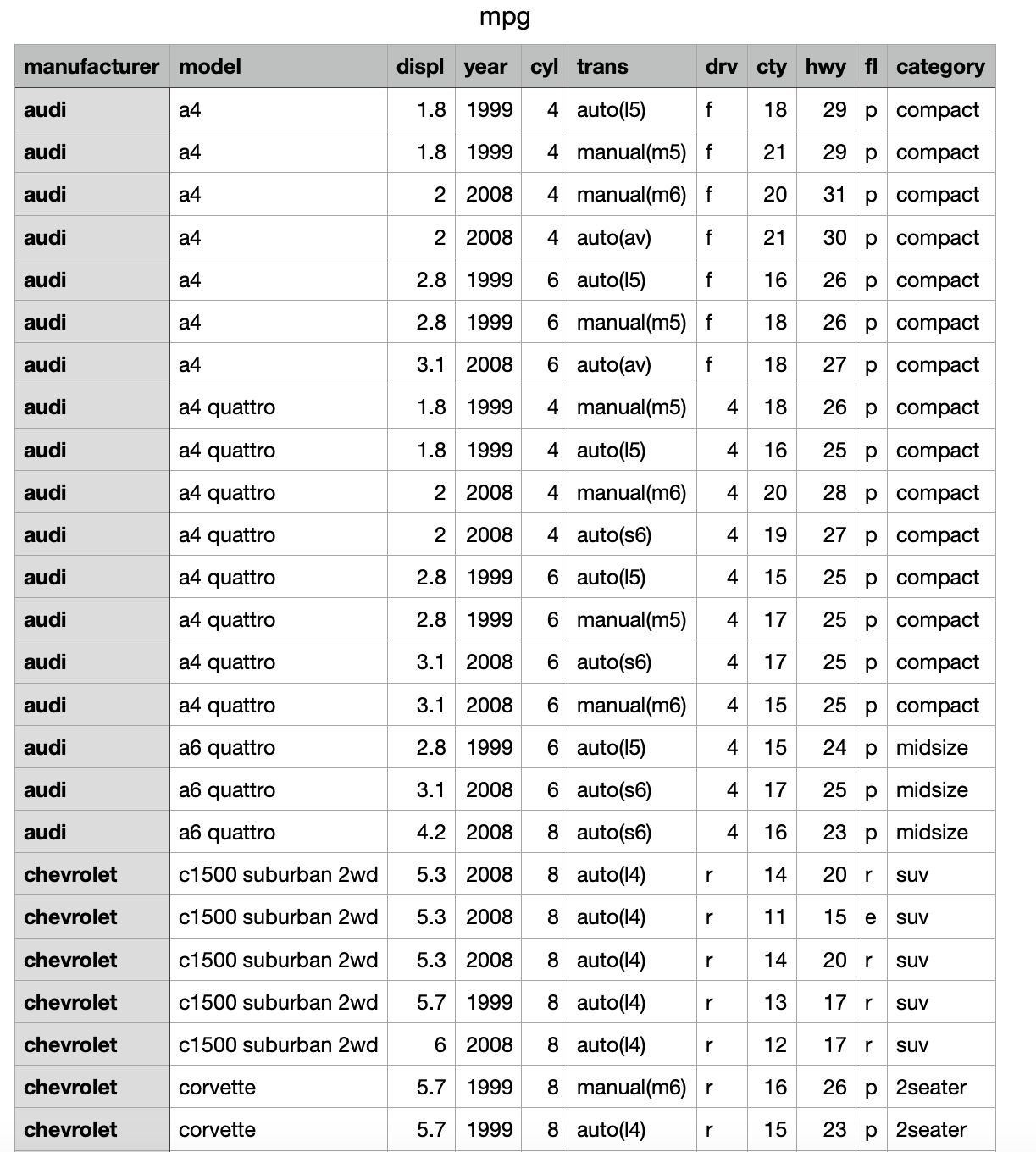
다루고자 하는 mpg.csv 는 이렇게 생겼다.
python으로 csv 파일을 다룰 때에는 import pandas as pd 코드를 이용해서 Pandas 패키지를 사용하면 된다.
1. 산점도 만들기
import seaborn as sns
sns.scatterplot() 를 이용해서
아래 코드는 mpg.csv를 파이썬으로 사용하는 코드이다.
sns.scatterplot(data=???, x='???', y='???')
이런 형식으로 적게 되는데 중요한 것은 x, y에는 data 파일에 들어있는 실제 이름을 넣어야 한다는 것이다. 내 마음대로 이상한 이름 넣으면 오류뜸. 내가 문자열 형태로 입력했는데 그걸 인식해서 data 파일에 있는 데이터를 가져와서 그래프를 그린다는게 진짜 신기했다 .. 위의 사진은 강의 슬라이드에 있는걸 똑같이 따라한건데 x, y 이름을 바꿔서 아래와 같이 응용 해볼 수도 있다.
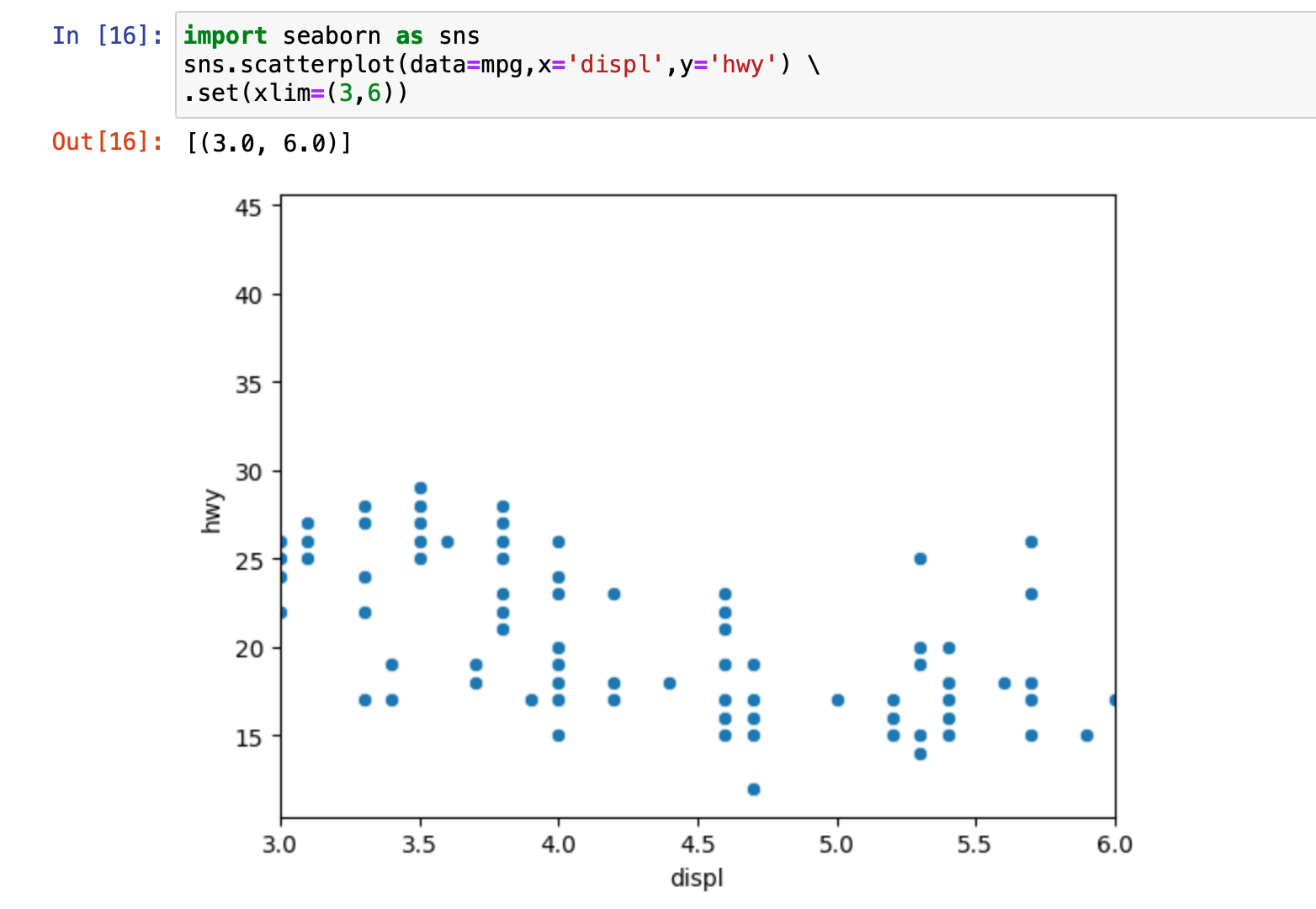
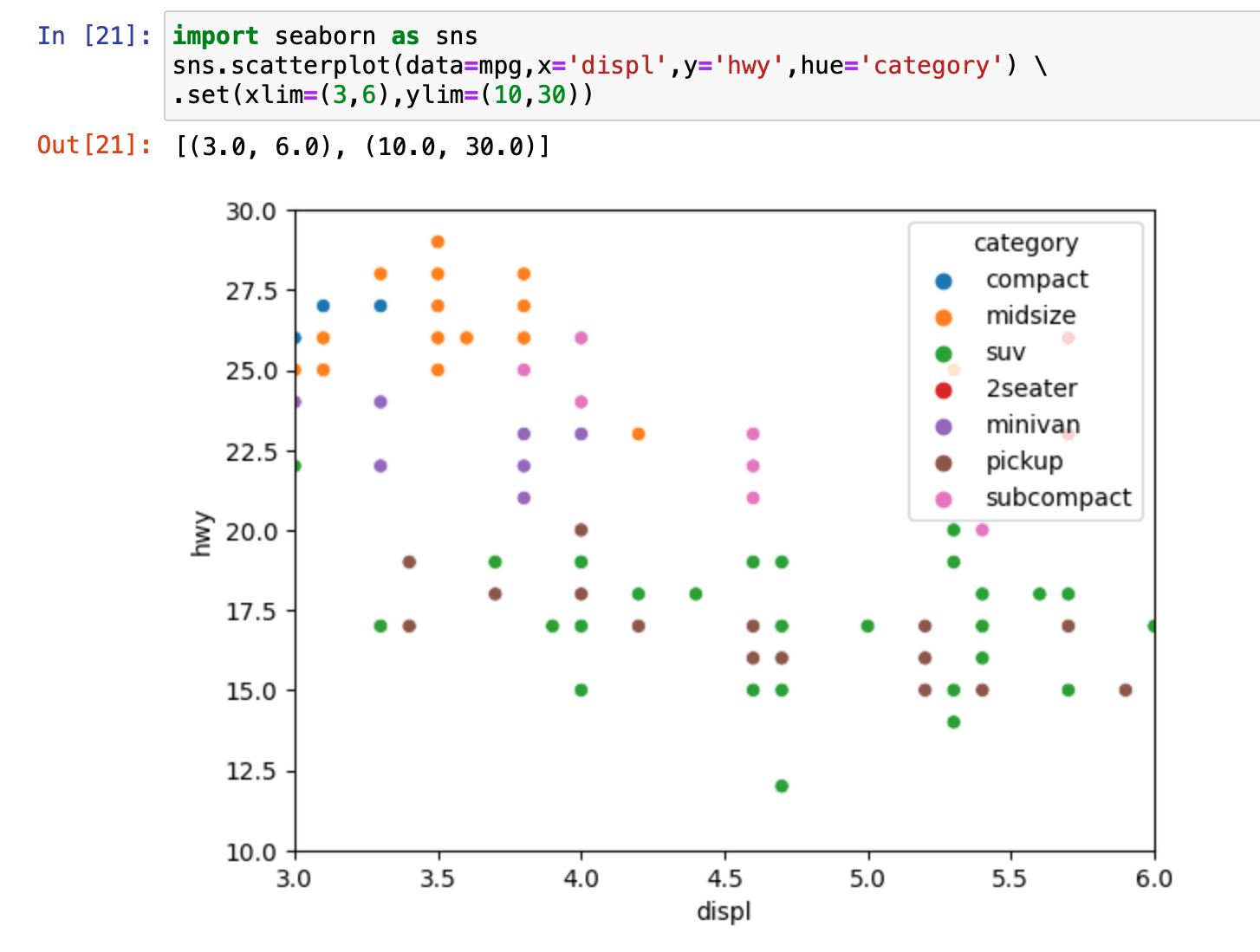
출력된 그래프의 여백이 마음에 안들거나 원하는 부분만 자세히 잘라서 보고 싶은 경우, x축 범위와 y축 범위를 제한할 수 있다. 축의 범위를 제한하는 코드는 아래와 같다.
sns.scatterplot(data=mpg, x='displ',y='hwy')\
.set(xlim=(3,6),ylim=(10,30))
\를 하고 한줄 띄고
.set() 안에 제한 내용을 넣어주면 된다.
xlim=(3,6) //3부터 6까지
이제 가독성을 높이기 위해 하나의 분류기준을 추가해서 색깔로 구분지어보자.
아래 코드는 scatterplot( ) 괄호 안에 hue = ' ' 항목을 추가했다. hue 안에 색깔로 구분 지을 분류기준을 넣으면 된다.
모든 설정 되돌리기
plt.rcParams.update(plt.rcParamsDefault)
2. 평균 막대 그래프 만들기
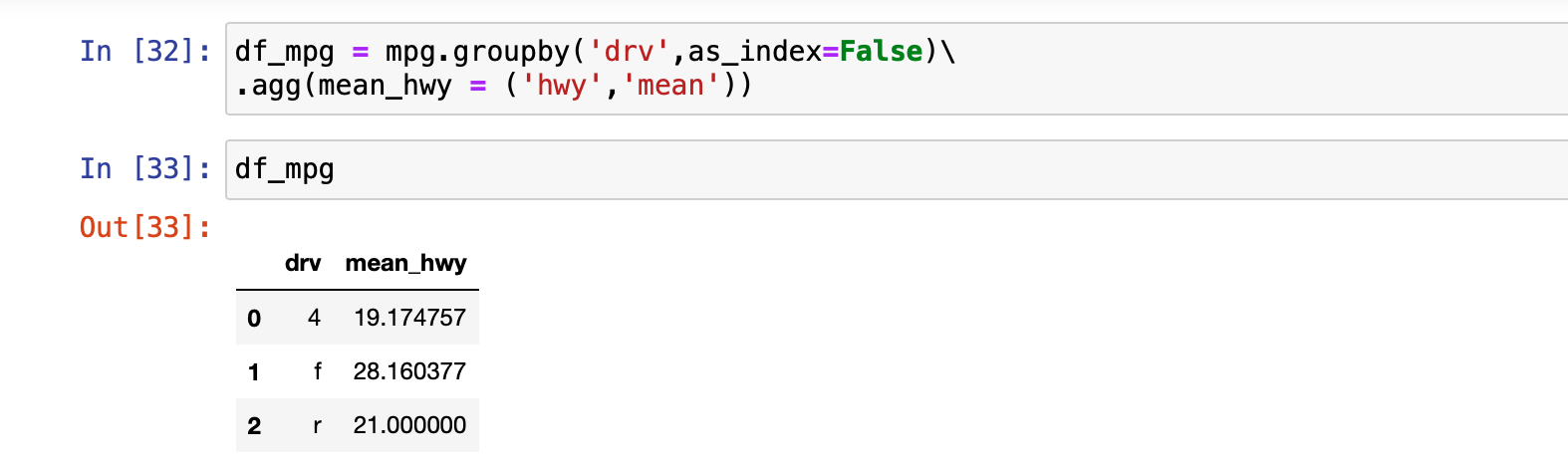
먼저 집단별 평균표를 만든다. drv별 분리, hwy 평균 구하기
as_index=False의 역할이 뭔지 이해하기 .. 이거 없으면 막대 그래프가 안나오고 에러뜬다.
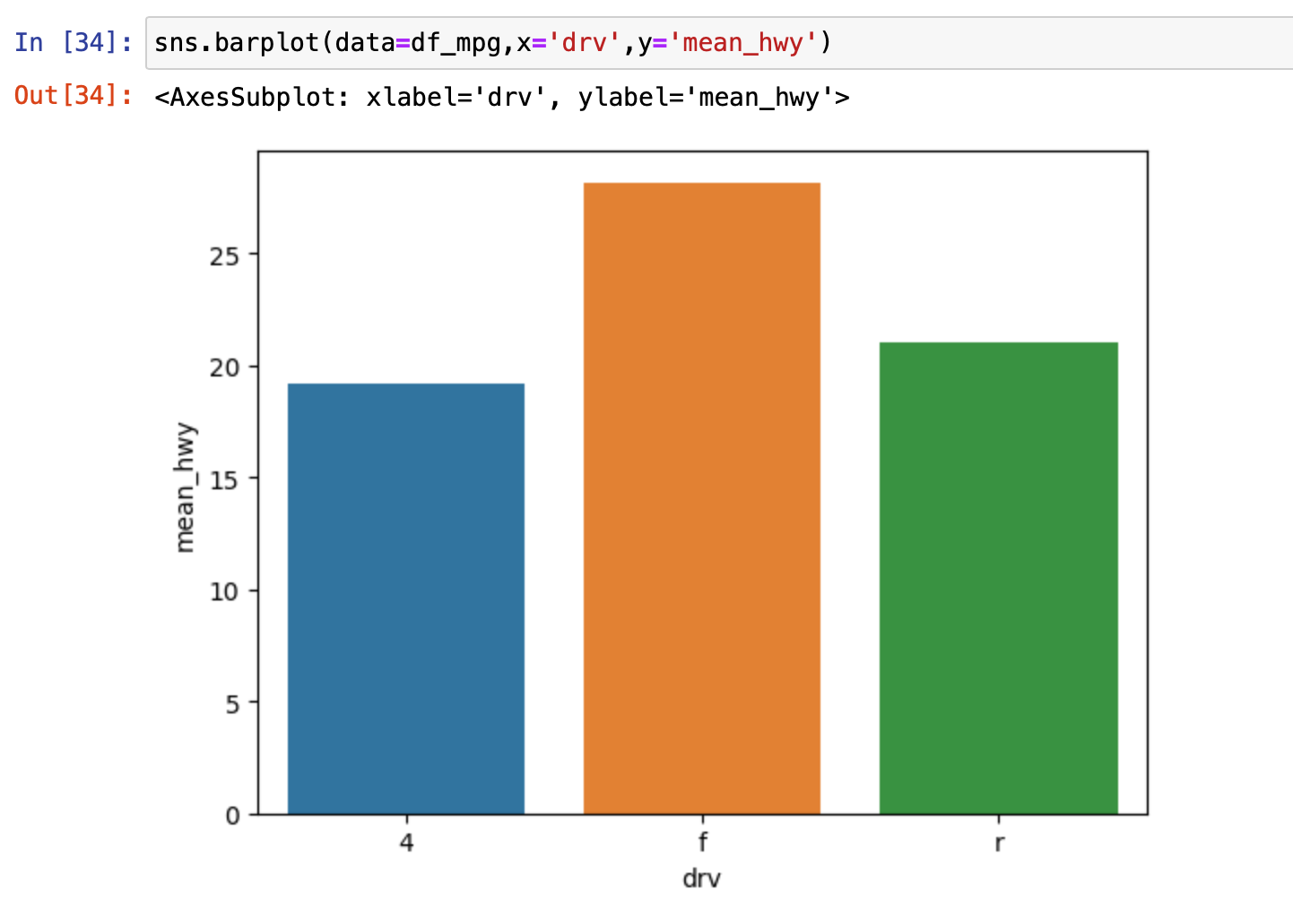
아까 mpg.csv를 이용했던 것처럼 위에서 우리가 만든 표를 data 로 이용해서 만들면 된다. 이번엔 막대그래프라서 barplot 을 대신 사용하면 된다.
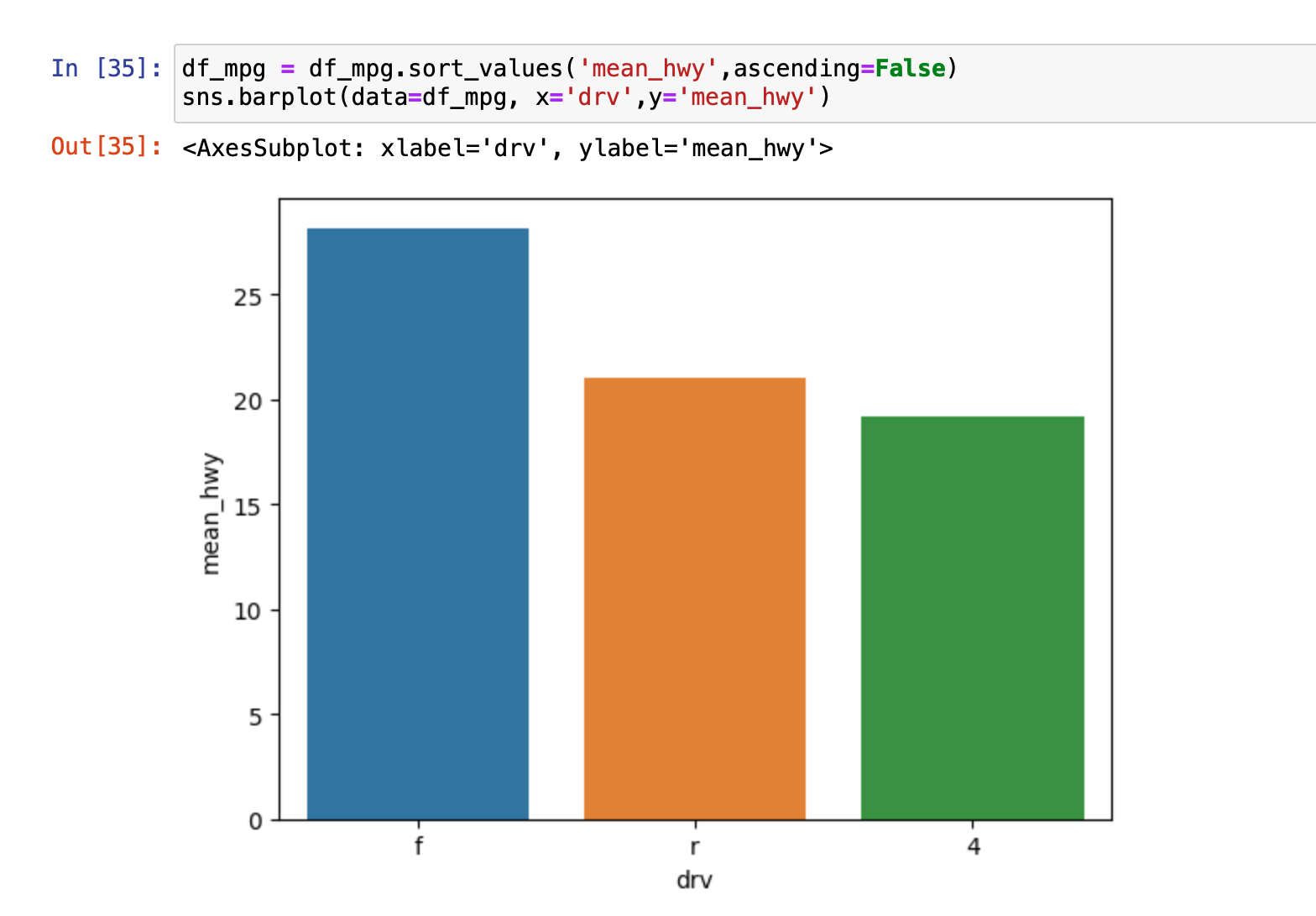
막대 그래프를 더 예쁘게 정렬하고 싶으면 data 자체를 정렬해줘야한다.
df_mpg = df_mpg.sort_values('mean_hwy', ascending=False)
로 내림차순으로 정렬하고 다시 막대그래프를 출력하면 다음과 같다.
3. 빈도 막대 그래프 만들기
먼저 집단별 빈도표를 만든다.
위에서 평균표를 만든 것과 코드 비교
4. 시계열 그래프 만들기
5. 상자 그림 만들기